
Concurrency, Parallelism, and Asynchronous Programming in Python

Last updated
In programming, there's often confusion between Concurrency and Parallelism. Initially, they might seem similar, but digging deeper shows they're quite different and affect how we build and improve our programs.
In this blog, we'll explore Concurrency and Parallelism to understand their dissimilarities. We'll see how they play crucial roles in tasks like web scraping and optimizing system calls, ultimately boosting performance.
What is Concurrency?
Concurrency, in simple terms, is managing multiple tasks simultaneously. Context switching is a fundamental mechanism for enabling concurrency.
Context switching refers to the process of saving the current state of a running task and temporarily shifting to another task from a queue. This allows the CPU, which can typically handle only one task at a time, to switch between tasks swiftly. While tasks may appear to be executing in parallel, the CPU is actually carrying out tasks concurrently, not in parallel.
Threads, which are lightweight processes capable of sharing memory, enable efficient context switching. This rapid switching between tasks gives the illusion of multitasking, but it's technically concurrent execution, not parallelism.
When it comes to programming, let's illustrate how concurrency works with a practical example:
Let's say we need to process over 200 pages as quickly as possible.
Here's our plan:
- First, we'll visit the Wikipedia page listing countries by population and extract the links of all the 233 countries mentioned there.
- Next, we'll visit each of these 233 pages and save the HTML content locally.
- Now, instead of using any concurrency or parallelism, we'll create multiple functions to get all the links. We'll follow a sequential method without utilizing concurrency or parallelism concepts.
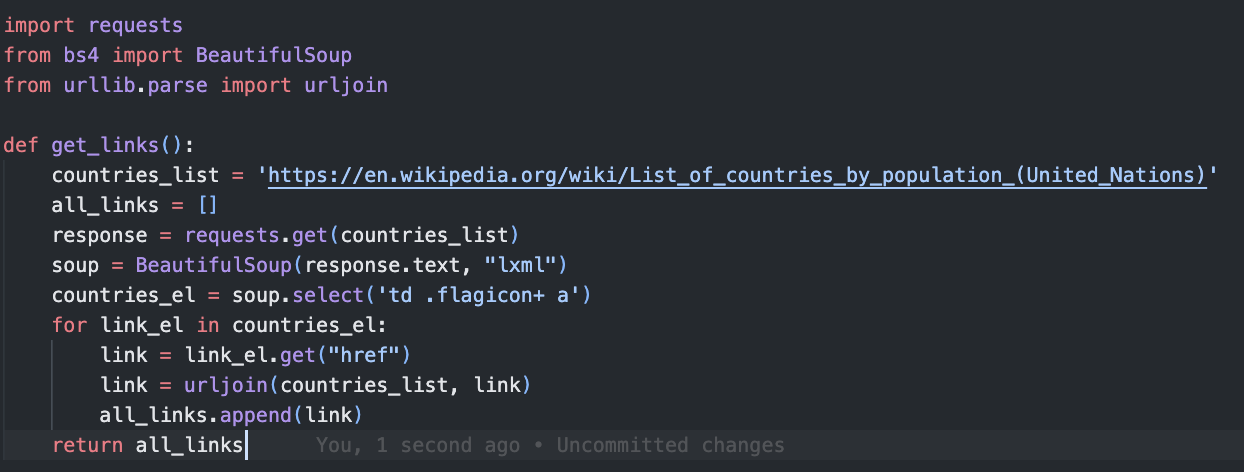
This function fetches the response from a link and uses BeautifulSoup to extract all links. It then converts these relative links to absolute links using urljoin.
Now, we'll create a function that downloads the HTML from all 233 links sequentially, without utilizing threading.
First, let’s create a function to fetch and save a link.

This function fetches the response from the provided link and saves it as an HTML file.
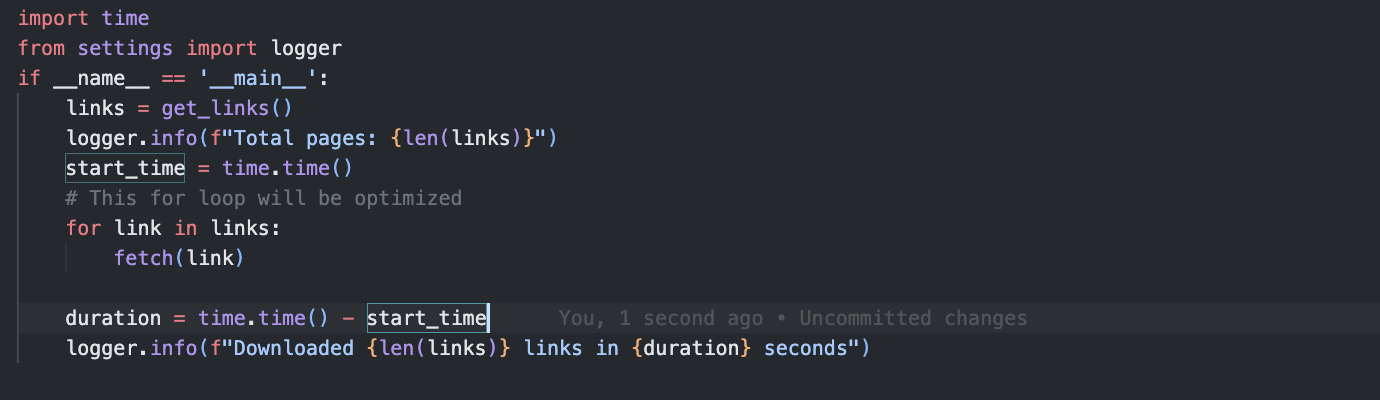
Finally, let’s call this function in a loop:
How Can We Use Concurrency to Speed up the Processes
Although we can create threads manually, we’ll have to start them manually and call the join method on each thread so that the main program waits for all these threads to complete.
A more efficient approach is to use the ThreadPoolExecutor class. This class is part of the concurrent.futures module. This class provides a simpler interface for creating and executing threads. Let's explore how to use:
First, we need to import ThreadPoolExecutor :
from concurrent.futures import ThreadPoolExecutor
Now, the for loop written above can be changed to the following:
with ThreadPoolExecutor(max_workers=16) as executor:
executor.map(fetch, links)
Here, the executor applies the function fetch to every item of links and yields the results. The maximum number of threads is controlled by max_workers argument.
It’s important to find the sweet spot for the max_worker. On our computer, if the max_worker parameter is changed to 32, the time comes down to 4.6 seconds.
Using Parallelism to Speed up the Process
While concurrency gives the impression of simultaneous execution in applications, parallelism goes further by enabling true multitasking across multiple CPU cores.
In contrast to concurrency, where tasks share the CPU's attention, parallelism utilizes multiple processors to execute tasks concurrently, resulting in significant performance improvements.
An example of parallelism is parallel computing, where multiple processors simultaneously handle numerous processes. This requires specialized programming known as parallel programming, where code is written to utilize multiple CPU cores. In parallel programming, more than one process is executed in parallel.
Let's revisit the task of downloading HTML from the 233 links.
In Python, parallelism can be achieved by using multitasking. It allows us to download several links at the same time by using several processors.
To write an effective code that can be run on any machine, you need to know the number of processors available on that machine.
Python provides a very useful method, cpu_count(), to get the count of the processor on a machine. This is very helpful to find the exact number of tasks that can be processed in parallel. Note that in the case of a multi-core CPU, each core works as a different CPU.
Let’s start with importing the required module:
from multiprocessing import Pool, cpu_count
Now we can replace the for loop in the synchronous code with this code:
with Pool(cpu_count()) as p:
p.map(fetch, links)
This will create a multiprocessing pool with a capacity matching the number of available CPUs. So, the maximum number of tasks executed concurrently will adjust dynamically based on the available CPUs at runtime.
This marks a considerable improvement over the synchronous approach, which took about 139 seconds.
If you're involved in incident management, Zenduty can enhance your MTTA & MTTR by at least 60%. With our platform, your engineers receive timely alerts, reducing fatigue and boosting productivity.
Sign up for a free trial today and see firsthand how you can achieve these results Additionally, you can also schedule a demo to understand more about the tool.
Divyanshu Singh
Along with Anjali Udasi
